I. Introduction
The COVID-19 pandemic has underscored the urgent need for efficient and scalable diagnostic tools to manage and contain viral spread. While stringent social measures and conventional testing methods have played a role in mitigating the initial waves, they haven’t eradicated the virus, and the looming threat of new outbreaks remains a global concern. The limitations of current viral and serology tests, particularly their cost and processing time, hinder widespread daily testing necessary for effective outbreak prevention. For instance, daily testing of the entire US population with current methods would incur billions of dollars, highlighting the impracticality of such an approach. Furthermore, the delay in obtaining results from these tests often necessitates isolation periods, disrupting daily life and economic activity.
In stark contrast, Artificial Intelligence (AI) offers a revolutionary pathway to pre-screening large populations rapidly and at minimal cost. Imagine a diagnostic tool capable of testing entire populations daily, or even hourly, at virtually no variable expense. This is the promise of AI-driven pre-screening, and it becomes particularly crucial when considering the limitations of current testing capacities. In mid-2020, the US daily testing capacity was significantly lower than expert-projected needs, emphasizing the necessity for high-throughput solutions. Our AI pre-screening tool presents such a solution, capable of intelligently prioritizing individuals for further testing, especially among asymptomatic carriers who are key drivers of transmission. Furthermore, when comparing accuracy, commercially available COVID-19 serology tests in the early stages of infection exhibit sensitivities ranging from 40-86%. Our AI-powered approach, however, achieves a remarkable 98.5% sensitivity, showcasing its potential to outperform existing methods in identifying positive cases.
The concept of widespread daily testing combined with effective contact tracing has been proposed as a viable alternative to broad confinement measures, potentially curbing viral spread without the severe economic repercussions of lockdowns. However, initial attempts at mass testing and contact tracing in some regions have fallen short, often due to a lack of agile, affordable, and coordinated public health strategies. As the virus continues to spread globally, particularly to regions with limited resources for extensive testing or prolonged lockdowns, a cost-effective, accurate, and large-scale pre-screening tool becomes paramount. This tool could efficiently guide the allocation of resources by prioritizing confirmatory tests and enabling rapid localized outbreak control. Recent advancements in AI have indeed proposed various applications to aid in pandemic management, underscoring the growing recognition of AI’s potential in this domain.
An AI-powered cough test offers a unique set of advantages that can address the shortcomings of biological testing. These advantages include: non-invasive operation, real-time results, negligible variable cost, accessibility for anyone with a smartphone or computer, and the capability for continuous patient monitoring.
Developing such an AI system necessitates both substantial training data and a robust modeling strategy. Recognizing the initial data scarcity, we launched a global crowdsourcing initiative to collect COVID-19 forced-cough audio recordings. Through our website, we gathered cough sounds alongside responses to a questionnaire addressing diagnosis and symptoms (detailed in Table I). This effort resulted in the MIT Open Voice COVID-19 Cough dataset, a landmark achievement as the largest audio health dataset of its kind, comprising 5,320 balanced subjects with and without COVID-19. For our research, we meticulously selected all COVID-19 positive cases and an equal number of randomly chosen negative cases from our extensive dataset to ensure a balanced and representative sample.
TABLE I. COVID-19 Subject Selection and Model Performance Across Diagnostic Sources, Symptoms, and Demographics. The Data Reflects Voluntary Screening Tool Usage Ratios.
| Categories | Positives | Negatives | Total |
|---|---|---|---|
| # | Hit(%) | # | |
| Number of Patients | 2660 | 94.0 | 2660 |
| COVID-19 Diagnostic Source | |||
| Official Test | 475 | 98.5 | 224 |
| Doctor Assessment | 962 | 98.8 | 523 |
| Personal Assessment | 1223 | 89.5 | 1913 |
| Symptoms | |||
| No Symptoms ‘Official’ | 102 | 100.0 | 114 |
| Asymptomatic (No Symptoms) | 196 | 100.0 | 2029 |
| Fever | 656 | 98.1 | 34 |
| Tiredness | 1428 | 93.2 | 210 |
| Sore Throat | 1064 | 99.9 | 205 |
| Difficulty Breathing | 680 | 99.3 | 49 |
| Chest Pain | 680 | 99.4 | 58 |
| Diarrhea | 652 | 94.2 | 100 |
| Cough | 1724 | 99.8 | 262 |
| Gender | |||
| Male | 1116 | 94.4 | 1263 |
| Female | 1308 | 94.6 | 1212 |
| Other | 236 | 93.8 | 185 |
| Alzheimer’s Diagnostic (for Biomarker Comparison) | |||
| Doctor Diagnostic | 78 | 100.0 | 78 |

Our modeling strategy was informed by our prior work on Alzheimer’s disease diagnosis and emerging reports of neurological symptoms in COVID-19 patients, such as neuromuscular impairment and anosmia. Unsuccessful initial attempts with basic CNN models led us to adopt the Open Voice Brain Model framework (OVBM), inspired by the MIT Center for Brains, Minds, and Machines’ Brain Model. This framework had previously demonstrated state-of-the-art accuracy (93.8%) in Alzheimer’s diagnosis. The MIT OVBM framework leverages orthogonal acoustic biomarkers for both diagnosis and creating personalized patient saliency maps for longitudinal monitoring.
The subsequent sections detail our data collection process (Section II.A), the architecture of our COVID-19 AI model (Section II.B), the four key biomarkers employed (Section II.C), and the results (Section III). The results section includes our model’s pre-screening performance, biomarker evaluation, and the utility of individualized patient saliency maps. Finally, Sections IV and V offer a summary, discuss limitations, and explore practical implications for deploying our COVID-19 pre-screening tool, including potential pooling strategies and the broader role of AI in future medicine.
II. Methods
A. COVID-19 Cough Dataset
With approval from the MIT COHUES Institutional Review Board, we initiated a global cough data collection endeavor in April 2020 via our website recording platform (opensigma.mit.edu). The goal was to establish the MIT Open Voice dataset for COVID-19 cough discrimination. We collected cough audio recordings of varying lengths (averaging three coughs per participant) along with responses to a ten-question multiple-choice survey. This survey gathered data on disease diagnosis, general participant information (age, gender, location), medical diagnosis details (timing, source – official test, doctor evaluation, or self-assessment), symptom information (fever, fatigue, sore throat, breathing difficulty, chest pain, diarrhea, cough), and symptom onset duration.
To date, our dataset includes approximately 2,660 COVID-19 positive cases and a 1:10 ratio of positive to control subjects. The platform’s browser and device compatibility minimized potential device-specific biases. All data was anonymized upon secure server collection, and audio samples were saved in uncompressed WAV format (16kbps bit-rate, single-channel, opus codec). Recordings lacking audio content (files of 44 bytes) were removed. Crucially, cough recordings were used for training and testing without any prior segmentation.
For balanced distribution, we used all available COVID-19 positive samples and randomly selected an equal number of COVID-19 negative samples. We applied two key inclusion criteria: diagnostic confirmation within the last 7 days and symptom onset no more than 20 days prior to sample collection, with symptoms persisting until recording. These forced-cough audio recordings and diagnostic results formed the basis for training and validating our COVID-19 discriminator. The dataset was divided into training (80%, 4256 subjects) and validation (20%, 1064 subjects) sets. Table I provides a detailed breakdown of patient distribution within the randomly sampled dataset.
B. COVID-19 Model Architecture Overview
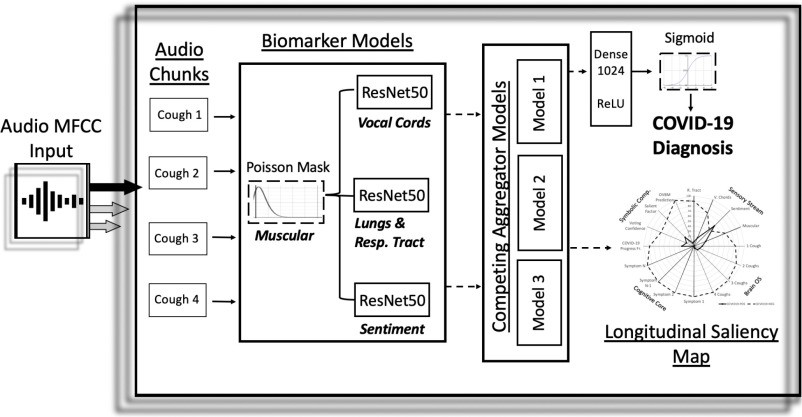
Our proposed model architecture, depicted in Figure 1, takes cough recordings as input and performs preprocessing before feeding them into a Convolutional Neural Network (CNN). The CNN outputs a pre-screening diagnostic result and a biomarker saliency map (as illustrated in Figure 3(c)).
Fig. 1. Architecture of the AI-Powered COVID-19 Cough Discriminator.
Overview architecture of the COVID-19 discriminator. Cough recordings are input to the model, resulting in a COVID-19 diagnosis and longitudinal saliency map. A similar architecture was previously employed for Alzheimer’s disease diagnosis.
Fig. 3. Biomarker Performance and Patient Saliency Map.
[
A. Layers required for biomarker models to surpass baseline COVID-19 discrimination performance. Fewer layers indicate higher biomarker relevance. “Complete” denotes the final integrated discriminator. B. Performance gain from incorporating the Cough biomarker and the impact of pre-training individual biomarker models. C. Explainable saliency map for longitudinal patient tracking, analogous to Alzheimer’s saliency maps. OVBM represents final model diagnostic. BrainOS shows model prediction aggregation for 1-4 coughs. COVID-19 progress factor indicates disease severity based on acoustic information needed for diagnosis. Voting confidence and salient factor reflect aggregate biomarker confidence and discrimination.
Preprocessing involves splitting each cough recording into 6-second audio segments, padding as necessary, and processing with Mel Frequency Cepstral Coefficient (MFCC) extraction. This MFCC data is then input into Biomarker 1. The subsequent CNN architecture consists of three parallel ResNet50 networks. The 7 × 7 × 2048 4-D tensor output layers from each ResNet50 are concatenated in parallel, as shown in Figure 1. In baseline models, these ResNet50s are not pre-trained. However, in our optimized model, they are pre-trained to capture acoustic features related to Biomarkers 2, 3, and 4, as detailed in Section II.C. The concatenated tensor output is then processed by a Global Average Pooling 2D layer, followed by a 1024-neuron dense layer with ReLU activation, and finally a binary dense layer with sigmoid activation for classification. The entire architecture is trained on the COVID-19 cough dataset for binary COVID-19/non-COVID-19 classification. Outputs from different chunks are aggregated using competitive schemes to generate the subject’s saliency map, as visualized in Figure 3(c). The results presented in Table I are solely based on the initial audio chunk outputs. Future research may explore the potential of aggregation to enhance both diagnostic accuracy and model explainability.
C. COVID-19 Model Biomarkers
The MIT Open Voice Medicine architecture leverages four biomarkers, previously validated for Alzheimer’s disease detection with state-of-the-art accuracy. These biomarkers, inspired by medical community insights, are: muscular degradation, vocal cord changes, sentiment/mood variations, and alterations in the lungs and respiratory tract.
1). Biomarker 1: Muscular Degradation
Building upon memory decay models, we incorporated features of muscle fatigue and degradation by applying a Poisson mask (Equation 1) to input signals for all training and testing data. Poisson decay, a natural phenomenon, has been previously proposed to model muscular degradation. We found this biomarker significant, as its removal approximately doubles the error rate in predictions based on official tests. To quantify muscular degradation’s influence, we developed a metric comparing model output with and without the Poisson step. This metric, a normalized ratio, is integrated into the saliency map (Figure 3). For COVID-19 negative cases, the metric is directly plotted; for positives, one minus the metric is plotted.
The Poisson mask applied to an MFCC point, Ix, is calculated by multiplying Ix with a random Poisson distribution parameterized by Ix and λ, where λ is the average of all MFCC values.
2). Biomarker 2: Vocal Cords
Lung diseases often manifest distinct vocal cord biomarker expressions compared to healthy individuals. For example, phonation threshold pressure, the minimum lung pressure for vocal fold oscillation, is linked to vocal fatigue. Therefore, we developed a vocal cord biomarker model to detect changes in fundamental vocal cord sound features in continuous speech.
We focused on training a Wake Word model for the universal sound “mmmmmm.” A ResNet50 was trained using MFCC input (shape: 300, 200) from the LibriSpeech audiobook dataset (≈1,000 hours of speech) to differentiate “Them” from other words. Trained on a balanced dataset of 11,000 two-second audio chunks (half containing “Them”), the model achieved 89% validation accuracy.
We discovered that features learned by this biomarker effectively detect vocal cord variations between COVID-19 and control subjects, correctly classifying 54% of the test set. Notably, for 19% of subjects, this was the sole biomarker providing correct classification (Table II).
TABLE II. Unique and Overlapping Detection Percentages of Individual Biomarkers for COVID-19 and Alzheimer’s.
| Biomarker Category | Model Name | COVID-19 (%) | Alzheimer’s (%) |
|---|---|---|---|
| Respiratory Tract | Cough | 23 | 9 |
| Sentiment | Intonation | 8 | 19 |
| Vocal Cords | Wake Word ‘THEM’ | 19 | 16 |
| R. Tract & Sentiment | Cough & Intonation | 0 | 0 |
| R. Tract & V. Cords | Cough & Wake Word | 1 | 6 |
| Sentiment & V. Cords | Intonation & Wake Word | 0 | 3 |
| All 3 Biomarkers | Combined Model | 34 | 41 |
| None of the 3 Biomarkers | Combined Model | 15 | 6 |
3). Biomarker 3: Sentiment
Research indicates cognitive decline in COVID-19 patients, and clinical evidence highlights sentiment’s importance in early neurodegenerative decline diagnosis. Different sentiments, such as doubt or frustration, can be indicative of neurodegenerative conditions. To capture this, we trained a Sentiment Speech classifier model on the RAVDESS dataset, featuring actors expressing eight emotions: neutral, calm, happy, sad, angry, fearful, disgusted, and surprised. A ResNet50 was trained on 3-second MFCC samples (shape: 300, 200) for 8-class intonation classification, achieving 71% validation accuracy.
4). Biomarker 4: Lungs and Respiratory Tract
Human cough sounds have proven valuable in diagnosing various diseases using automated audio recognition. Respiratory infections alter the physical structure of the lungs and respiratory tract. Historically, auscultation of the lungs during forced coughs was part of COVID-19 diagnostic procedures. AI analysis of forced coughs holds promise for diagnosing numerous diseases. An algorithm by [35] uses audio recognition to diagnose Pertussis, a potentially fatal respiratory disease. Smartphone-based cough sound analysis is already being used to diagnose pneumonia, asthma, and other conditions with high accuracy. Therefore, a biomarker model capturing lung and respiratory tract features was selected.
Previous models we developed using a superset of the MIT Open Voice cough dataset for COVID-19 detection accurately predicted gender and native language from a single cough. We hypothesized that models trained to differentiate native language from cough sounds could enhance COVID-19 detection through transfer learning. We trained a ResNet50 on binary English vs. Spanish language classification using 6-second audio chunks (MFCC input shape: 600, 200), achieving 86% accuracy. We found this cough biomarker to be the most relevant, providing 23% unique detection and 58% overall detection (Table II).
III. Results
A. COVID-19 Forced-Cough Discrimination Accuracy
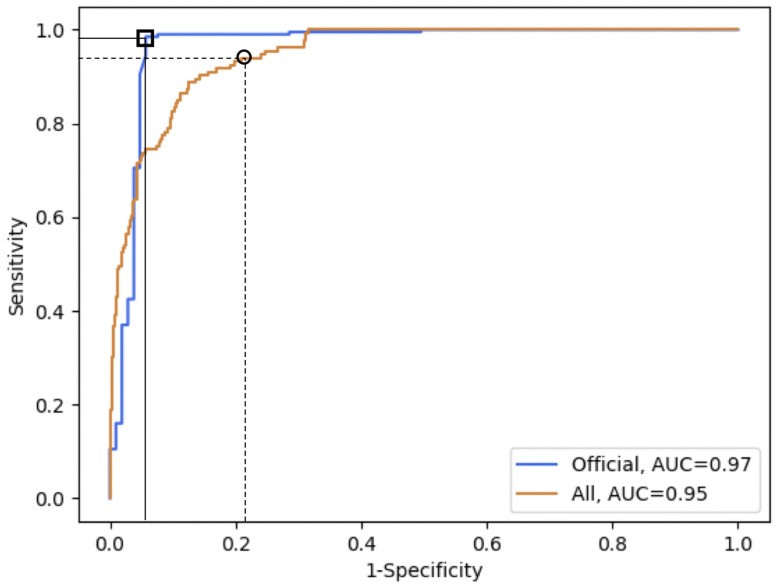
Our model achieves a 97.1% discrimination accuracy for subjects diagnosed with an official COVID-19 test. The 18% accuracy gap between officially tested and self-diagnosed subjects (Table I) suggests self-diagnosis inaccuracies contribute to virus spread, even with good intentions. Our tool could mitigate this impact. Remarkably, our model correctly identifies 100% of asymptomatic COVID-19 positive individuals, with a false positive rate of 16.8%. Importantly, the model’s sensitivity and specificity can be adjusted based on the specific application (Figure 2).
Fig. 2. ROC Curves for COVID-19 Detection.
ROC curves for COVID-19 detection on officially tested subjects (orange, square markers) and the entire validation set (blue, circle markers). The orange curve shows AUC 0.97. Markers indicate chosen thresholds: 98.5% sensitivity and 94.2% specificity (official tests) and 94.0% high sensitivity (validation set). Thresholds can be adjusted based on use case.
B. Biomarker Saliency Evaluation
To assess each biomarker’s role, we compared a baseline model (same architecture but without pre-training) to our complete model, both with and without individual biomarkers. The baseline model, with identical architecture but random initialization instead of pre-trained weights, serves as a point of comparison. Figure 3(a) shows the respiratory tract biomarker model requires minimal fine-tuning to surpass baseline performance, highlighting its pre-learned feature relevance. Sentiment, however, requires more retraining, suggesting less direct relevance despite some value. Figure 3(b) demonstrates leave-one-out significance by measuring performance loss upon biomarker removal. The vocal cord biomarker’s removal causes twice the accuracy loss compared to sentiment.
Table II further illustrates biomarker contributions, showing the percentage of unique patients identified by each. This consistency confirms that each biomarker model provides complementary features. This suggests that incorporating additional biomarkers could further enhance the diagnostic accuracy and explainability of the MIT OVBM AI architecture for COVID-19. The low overlap in unique subject detection between biomarker pairs reinforces their orthogonality.
Beyond diagnostic accuracy, our AI biomarker architecture outputs explainable insights for clinicians via a patient saliency map (Figure 3(c)). The Sensory Stream displays biomarker expressions. BrainOS tracks model confidence improvement with increasing cough inputs, indicating diagnosis strength and potential disease severity. Symbolic Compositional Models provides composite metrics based on Sensory Stream and BrainOS data. These modular metrics enable longitudinal patient monitoring using the saliency map and facilitate biomarker research and metric development. Future research may determine the model’s ability to detect disease resolution and loss of contagiousness in COVID-19 positive individuals.
IV. Discussion
Our research demonstrates the potential of AI and forced-cough analysis for highly accurate (98.5%) COVID-19 discrimination. Notably, our model detected 100% of asymptomatic COVID-19 positive cases, aligning with other studies highlighting speech’s diagnostic value.
The striking similarity in biomarker utility for both Alzheimer’s and COVID-19 detection is a significant finding. The same biomarkers effectively discriminate both conditions, suggesting the existence of higher-level biomarkers applicable across seemingly disparate medical specialties. This supports collaborative data collection approaches like the MIT Open Voice initiative.
This initial model development phase focused on large-dataset training to learn effective COVID-19 cough discrimination features. While self-reported and doctor-assessed diagnoses may introduce labeling inaccuracies, they provide the data diversity and volume essential for model robustness and bias reduction. The high accuracy on officially tested subjects suggests similar real-world deployment accuracy. Ongoing clinical trials in multiple hospitals are underway to validate this. Further data collection efforts will refine and validate the model.
Considering cultural and age-related cough variations, future model development could focus on tailoring the model to specific demographics using collected metadata and potentially incorporating other modalities like vision or natural language symptom descriptions.
Cough segmentation’s impact on results warrants investigation. For diagnostic validity, cough recording verification is crucial. In our dataset, manual sorting was needed to remove a few speech recordings mislabeled as coughs, highlighting the need for automated cough vs. speech discrimination.
This non-invasive, free, and real-time pre-screening tool holds significant potential to complement COVID-19 containment efforts in both low and high prevalence areas. It can mitigate asymptomatic spread. The MIT Open Voice approach can augment healthcare systems, particularly when combined with open collaborative initiatives like the Open Voice Network. Potential use cases include:
-
Daily Population Screening Tool: For workers returning to workplaces, students to schools, and commuters using public transport, a scalable screening method, especially for asymptomatic individuals, is crucial. Thermometer-based screening is limited, detecting fever in only 45% of mild-moderate cases (9% of all COVID-19 positives, including asymptomatics). Our tool, however, detects 98.5% of COVID-19 positives, including all asymptomatic cases, offering a significantly more effective screening solution.
-
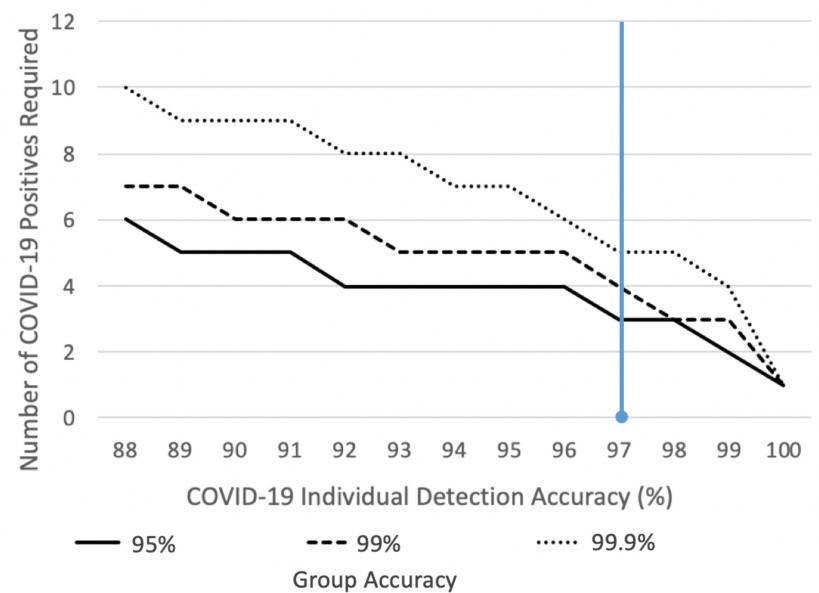
Pre-selection for Test Pooling: Test pooling is a strategy for efficient resource utilization, particularly in low-incidence areas. Our tool, used for pre-screening groups like classrooms or factories, could rapidly identify groups with a higher likelihood of infection, enabling targeted and efficient test pooling. Figure 4 illustrates this concept.
Fig. 4. Group Pre-screening for Efficient COVID-19 Detection.
Group pre-screening effectiveness in low-prevalence settings. The graph shows false positive rates for groups of 25 people based on the required number of positives for a group to be flagged. Current model accuracy (blue line) requires 3 positives in a group of 25 to maintain a 1% false positive rate for uninfected groups. Improved model accuracy reduces the required number of positives. Example: in a 2500-student campus, only 25 groups (classes) would require further testing until an outbreak occurs (3+ cases in a class), at which point the screening alerts. In a low-incidence country like New Zealand, using a 99.9% accurate group test (requiring 5 positives), only 2000 groups out of 2 million would be falsely flagged, significantly reducing false positives and costs compared to individual PCR testing.
- COVID-19 Testing in Resource-Limited Regions: COVID-19 test availability is globally uneven. Many regions lack resources for widespread PCR or serology testing. Our pre-screening tool offers a potentially transformative solution for large-scale detection in resource-constrained areas, crucial for global pandemic control.
V. Conclusion
We have developed an AI pre-screening test that achieves 98.5% accuracy in COVID-19 detection from forced-cough recordings, including 100% detection of asymptomatic cases. This tool is low-cost and provides a saliency map for longitudinal explainability.
A group outbreak detection tool derived from this model can pre-screen entire populations daily, avoiding the expense of individual testing, particularly valuable in low-incidence settings where post-test isolation is less justifiable. Figure 4 demonstrates that our model, when adapted for group testing, can detect COVID-19 presence in 99.9% of 25-person groups with 5 positive cases and 95% of groups with 3 positives.
Ongoing clinical trials with hospitals globally (Mount Sinai, White Plains Hospitals (US), Catalan Health Institute (Catalonia), Hospitales Civiles de Guadalajara (Mexico), Ospedale Luigi Sacco (Italy)) are established to further refine and validate our tool. This data will drive model improvement and pandemic management strategies. Figure 4 highlights that improving individual model accuracy significantly reduces the number of positives needed for group test detection, emphasizing the need for larger datasets and model refinement.
We have partnered with a Fortune 100 company to demonstrate our tool’s value in real-world COVID-19 management. Future research will focus on tailoring the model to diverse demographics and exploring multimodal inputs.
We hope our methods inspire similar AI-driven disease management approaches beyond dementia and COVID-19, potentially expanding our set of orthogonal audio biomarkers. Following the MIT Open Voice approach, we envision voice data, potentially from smart devices, becoming broadly available for continuous pre-screening, possibly integrated with other modalities like vision and EEG. Proactive, always-on pre-screening tools, constantly refined, could make future pandemics a thing of the past. “Wake Neutrality,” as discussed in [44], may be a pathway to realize this vision while addressing associated legal and ethical considerations.
Contributor Information
Jordi Laguarta, Email: [email protected].
Ferran Hueto, Email: [email protected].
Brian Subirana, Email: [email protected].