Introduction
In the realm of research, particularly within fields like aphasiology, the clarity and operational definitions of constructs are paramount. They ensure that research findings are both meaningful and readily interpretable. Aphasia, a condition frequently encountered in this field, is often broadly defined as “an acquired language disorder, commonly resulting from brain injury, that impairs both expressive and receptive language abilities.” However, this definition, while widely accepted, often lacks the specificity needed for in-depth study and clinical application. To deepen our understanding of what constitutes aphasia, this paper undertakes a content analysis of six prominent diagnostic aphasia tests. Among these, we will pay particular attention to the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA), alongside the Porch Index of Communicative Ability, the Boston Diagnostic Aphasia Examination, the Western Aphasia Battery, the Comprehensive Aphasia Test, and the Quick Aphasia Battery. These tests are not only historically significant but also remain in regular use in clinical and research settings today.
Our initial hypothesis was that the content of these aphasia tests would exhibit substantial similarity, given their shared objective of identifying and characterizing aphasia. We anticipated that any variations in test content would likely be subtle, primarily stemming from differences in the test creators’ epistemological perspectives on aphasia. Contrary to this expectation, our analysis revealed predominantly weak Jaccard indices, a measure of similarity, between the test targets across these batteries. Strikingly, only five test targets were consistently present across all six aphasia tests: auditory comprehension of words and sentences, repetition of words, confrontation naming of nouns, and reading comprehension of words. These qualitative and quantitative results suggest that the content variability among aphasia tests is more pronounced than initially anticipated. We conclude by discussing the implications of these findings for the field of aphasiology. This includes emphasizing the critical importance of continually updating and refining the operational definition of aphasia through collaborative discussions with a wide range of stakeholders, including researchers, clinicians, and individuals affected by aphasia.
Keywords: aphasia, test development, assessment, construct
“The Naming of Cats is a difficult matter, It isn’t just one of your holiday games; You may think at first I’m as mad as a hatter When I tell you, a cat must have THREE DIFFERENT NAMES.”
T.S. Elliot
Depending on the context, aphasia is commonly defined as an acquired language disorder resulting from brain injury that impacts expressive and receptive language. However, McNeil & Pratt (2001) highlighted the limitations of this broad definition, and ongoing international efforts are dedicated to establishing a more precise definition of aphasia for both research and clinical purposes (Berg et al., 2022). Key aspects under consideration for the operationalization of aphasia include its dimensionality (e.g., specific dimensions and their number; Halai et al., 2022), the role of cognitive processes (e.g., Minkina et al., 2017; Villard & Kiran, 2017), the inclusion of aphasia’s consequences (such as activity, participation, and psychosocial impacts; Berg et al., 2022; Martin et al., 2007), and its etiology (e.g., focal versus diffuse lesions; Berg et al., 2022).
The operational definition of aphasia significantly shapes the design and application of diagnostic tests, such as the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA) (Spreen & Risser, 2003), and influences approaches to aphasia rehabilitation. As Schuell (1964) aptly stated, “what you do about aphasia depends on what you think aphasia is” (p. 138). Furthermore, an operational definition inherently dictates what falls outside the scope of study (Petheram & Parr, 1998). Therefore, continuous examination and refinement of the definition of aphasia is crucial. A lack of conceptual clarity can lead to “measurement heterogeneity, measurement flexibility, and the profusion of untested measures” (Flake & Fried, 2020, p. 460). The relationship between operationally defining a construct and its assessment is symbiotic (Scheel et al., 2021). If the content captured by aphasia diagnostic tests, including the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA), lacks clarity, our understanding of aphasia and, consequently, its rehabilitation will be negatively impacted. Thus, this paper aims to analyze the content of aphasia diagnostic batteries as a window into how the field historically and currently defines aphasia.
Validity theorists agree that test validation requires a thorough explanation of the mechanisms producing observed response outcomes, whether through causal relationships between an attribute and a response (Borsboom et al., 2004) or the processes determining responses to individual items (Zumbo, 2009). Zumbo (2009, p. 71) states, “validity, per se, is not established until one has an explanatory model of the variation in item responses and/or scale scores and the variables mediating, moderating, or otherwise affecting the response outcome.” Test validity extends beyond convergent correlations with other tests, considering how underlying theories shape these tests (Zumbo, 2009). Our focus is limited to language impairment, as dominant diagnostic tests for aphasia, including the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA), have historically conceptualized aphasia primarily as a language disorder.
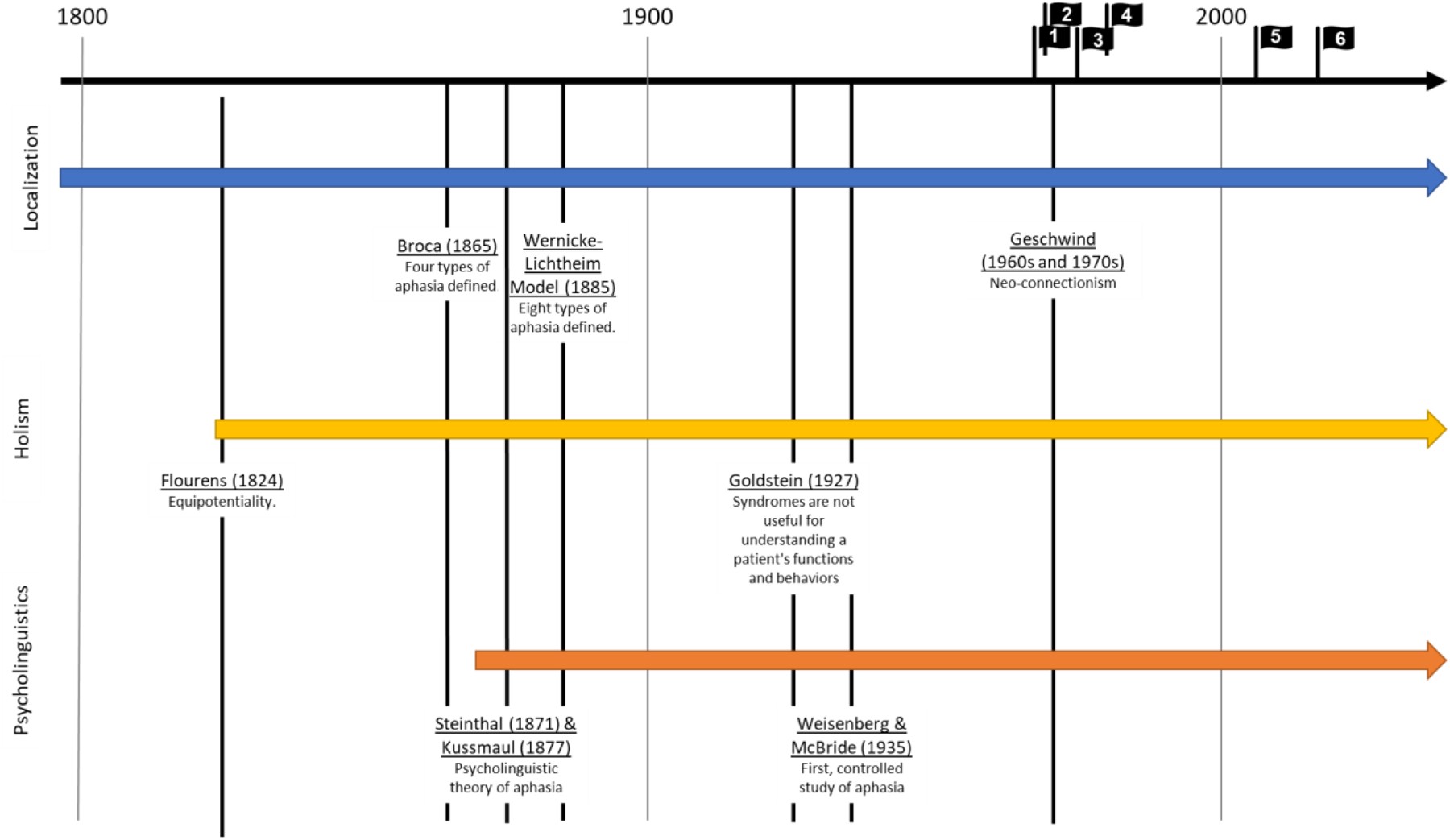
Understanding the field’s perspective on aphasia necessitates considering the long history of diverse epistemological influences and debates (Petheram & Parr, 1998). While a comprehensive historical account is beyond this paper’s scope (see Tesak & Code, 2008), we will outline three major epistemological streams in the field (Figure 1) and their influence on our current understanding of aphasia.
Figure 1.
The first stream is the localizationist approach, emphasizing brain-behavior relationships in language impairment. This is unsurprising, given that aphasia definitions often include “acquired” and “brain injury.” This perspective led to classical aphasia subtypes (Broca’s, Wernicke’s, Conduction), defined by Wernicke and Lichtheim (Lichtheim, 1885) and still used today (Graves, 1997).
The second stream is holism, arguing that language is distributed in the brain, opposing localizationism. Holists argue that localization-based subtypes are not useful clinically (Friedrich, 2006; Joswig & Hildebrandt, 2017; Tremblay & Dick, 2016). They also emphasize the broader impact of aphasia on the individual, including psychosocial effects (Goldstein, 1927), paving the way for the life participation approach (Chapey et al., 2000).
The third stream is psycholinguistics, emerging from the psychology of language, applied to aphasiology in the late 1800s (Steinthal, 1871), also opposing localizationism. Psycholinguists stressed understanding what is localized, focusing on linguistic domains impacted by aphasia (Spreen, 1968).
These diverse perspectives, along with the foundational work of Weisenberg & McBride (1935) in systematically assessing language and cognition, led to the development of several diagnostic aphasia tests in the 1960s and 70s, some still popular today, including the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA). Initially, these batteries heavily focused on language impairment, reflecting the then-current definition of aphasia. The localizationist influence grouped tests based on their alignment with or opposition to this epistemology. For this paper, we selected a series of diagnostic tests based on this categorization: The Boston Diagnostic Aphasia Examination (BDAE; Goodglass & Kaplan, 1972), the Western Aphasia Battery (WAB; Kertesz, 1979), and the Quick Aphasia Battery (QAB; Wilson et al., 2018) as historically and currently dominant tests embodying localizationist principles (or brain-behavior relationship importance). Conversely, we selected the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA; Schuell, 1964), the Porch Index of Communicative Ability (PICA; Porch, 1967), and the Comprehensive Aphasia Test (CAT; Swinburn et al., 2004) as tests developed in opposition to localizationism. Table 1 provides a brief summary of each test.
Table 1.
Selected diagnostic aphasia tests.
| Diagnostic Test | Versions | Assessment of Aphasia | Subtest Structure |
|---|---|---|---|
| Localizationist: Boston Diagnostic Aphasia Examination (BDAE), Western Aphasia Battery (WAB), and Quick Aphasia Battery (QAB) | |||
| BDAEBDAE-2 BDAE-3 | Goodglass & Kaplan (1972) Goodglass & Kaplan (1983) Goodglass, Kaplan, & Barresi (2000) | Aphasia diagnosis is based on the neuroanatomical localizationist works of Geschwind and others, resulting in classification of patients by aphasia subtype (e.g., Broca’s , Wernicke’s) and severity | Fluency; Auditory comprehension; Naming; Oral reading; Repetition; Automatic Speech; Reading comprehension; Writing |
| WABWAB-Revised | Kertesz (1979) Kertesz (1982) Kertesz (2007) | Connected speech; Auditory comprehension; Repetition; Naming; Reading; Writing; Apraxia; Construction, visuospatial, and calculation tasks | |
| QAB | Wilson et al. (2018) | Aphasia is multidimensional, and diagnosis must reflect the neural and functional mechanisms that are impaired and spared with aphasia. | Level of consciousness; Connected speech; Word comprehension; Sentence comprehension; Picture naming; Repetition; Reading aloud; Motor speech |
| Non-localizationist: Minnesota Test for the Differential Diagnosis of Aphasia (MTDDA), Porch Index of Communicative Ability (PICA), and Comprehensive Aphasia Test (CAT) | |||
| MTDDA | Schuell (1964) | Aphasia is a unitary disorder defined as a hierarchy of language deficits (Schuell & Jenkins, 1959) | Auditory; Visual and reading; Speech and language; Visuomotor and writing; Numerical relations and arithmetic processes (e.g., indicate coins for correct change, set clock, arithmetic problems) |
| PICA | Porch (1967) | Aphasia diagnosis is determined by considering the modality and quality of responses jointly along five dimensions: accuracy, responsiveness, completeness, promptness, and efficiency (by which Porch meant intelligibility or lack of distortion) | Verbal; Auditory; Reading; Writing; Copying; Pantomime |
| CATCAT-2 | Swinburn, Porter, & Howard (2004) Swinburn, Porter, & Howard (2023) | A psycholinguistic approach that considers input-output modality and variables such as imageability, frequency, and word length, in the development of test items. | Cognitive Screen; Comprehension of Spoken Language (Words, Sentences, Paragraphs); Comprehension of Written Language (Words, Sentences); Repetition; Spoken Language Production; Spoken Picture Description; Reading Aloud; Writing; Written Picture Description |
Continued research on linguistic and cognitive domains and neural processes in aphasia (e.g., Halai, et al., 2022; Lacey et al., 2017), and calls for better translation of diagnostic tests into practice (Byng et al, 1990; Nickels, 2005) indicate that a clear operational definition of aphasia remains elusive. Even the recent progress by Berg et al. (2022), in collaboration with the Collaboration of Aphasia Trialists, to produce a modern definition, highlights ongoing disagreements. Given that diagnostic tests 1) identify condition presence and 2) detail condition nature, their content is crucial for understanding how aphasia is defined in the field, and this is particularly relevant for the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA).
While current validity views prioritize construct validity (Zumbo, 2009), validity is considered a unitary property supported by various evidence types, including test content (AERA, APA, NCME, 1999; Messick, 1995; Sireci, 1998). We used Fried’s (2017) methodology to statistically investigate content overlap among depression scales, adapting it to examine the content of the six aphasia tests. We anticipate some content variation due to epistemological differences; otherwise, a single test would suffice. However, we also expect a core content set consistent across tests, as they assess the same construct – aphasia, or at least language impairment. This core content may implicitly define a field-accepted operational definition of aphasia, potentially needing updates based on current research and perspectives, including insights from the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA).
Method
Materials
We analyzed data from six aphasia tests: the MTDDA, PICA, BDAE-3, WAB-R, CAT, and QAB. We used the most recent versions available (note: CAT-2 was pre-order only at manuscript submission). Given the historical influences on aphasia operationalization, our focus was on the language and language-related processes (test targets) assessed in each test. We excluded the CAT Disability Questionnaire but included WAB Parts 1 and 2 (Supplemental) and the QAB extended version. While these may not be the most common clinical administrations, we aimed for maximal inclusion of impairment-based test targets for this content analysis, considering language impairment’s historical prominence in aphasia definitions, especially in tests like the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA). We also note that these tests primarily focus on acquired aphasia, not neurodegenerative aphasia (e.g., Primary Progressive Aphasia).
Procedure
To determine content similarities and differences across diagnostic aphasia tests, including the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA), we employed a label convergence process. This process aimed to unify similar domains (e.g., auditory comprehension) and test targets (e.g., spoken word comprehension, spoken sentence comprehension) under common labels. For each aphasia test, we consulted manuals and test materials to ensure the accuracy of our label convergence. Due to copyright restrictions, we cannot provide verbatim protocol instructions or specific trials. Instead, we present general domain and test target labels in our data tables and methodology examples to illustrate our coding process, consistent with other research using these diagnostic batteries.
First, NC extracted test targets from each test, including the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA), and identified similarities across tests. These similarities guided the creation of common labels for test targets. For instance, consider word repetition assessment. The MTDDA includes “repeating monosyllables.” PICA has “imitative naming.” BDAE includes “repetition of single words.” WAB, CAT, and QAB have “repetition of words.” Upon examining clinician prompts and trial-level stimuli in each assessment’s manual, we determined that these test targets all measure “word repetition” using similar stimuli (specific nouns) and instructions, despite varying terminology. Therefore, we relabeled each of these test-specific targets to the common label “repetition of words” for data analysis.
Second, during relabeling, NC differentiated test targets by stimulus type (e.g., words vs. nonwords) and complexity (e.g., simple vs. complex nouns). Many batteries already included this information in manuals or defined targets by these properties. For example, repetition test targets varied by stimulus type and complexity, including words, nonwords, complex words, phrases, sentences, and digits. We maintained separate common labels for each variation of repetition. Occasionally, distinct test targets in a battery were merged if practically indistinguishable (i.e., test-specific targets were merged). For instance, PICA’s “matching picture with object” and “matching object with object” were combined into “visual matching.” Again, NC carefully examined clinician prompts and trial-level stimuli to decide when to separate or merge targets, especially considering the unique approach of the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA).
To ensure inter-rater reliability in test target relabeling, SAA independently assessed common labels, verifying consistency with original manuals and materials, including those of the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA). Discrepancies were minimal (n = 5). NC and SAA resolved all discrepancies by re-examining manuals and stimuli to reach consensus.
Lastly, common test targets were grouped into broader domains. As anticipated, based on historical and theoretical underpinnings, domain specifications were similar but not entirely consistent across tests, including the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA), primarily due to terminology and specificity differences (see Table 1). Common domain labels were decided upon first. NC considered: 1) domain descriptions in test manuals, 2) current domains for aphasia classification (fluency, auditory comprehension, repetition, naming), 3) spoken vs. written language distinction, and 4) inclusion of praxis and cognitive domains supporting language. SAA reviewed relabeled domains and found no issues.
Then, NC assigned test targets to relabeled domains. We attempted to keep targets within their battery-specified domains. However, some tests, like the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA), had broader domains encompassing targets across multiple new relabeled domains. SAA reviewed all target-domain assignments and found no concerns.
For a concrete example, consider PICA’s “Verbal” domain with targets: describes function, names object, sentence completion, and imitative naming. “Describes function” was relabeled “novel sentence generation” (domain: discourse/speech). “Names object” became “confrontation naming – nouns,” and “sentence completion” retained its label (domain: verbal naming). “Imitative naming” became “repetition – words” (domain: repetition). Thus, PICA’s Verbal domain targets fell into Discourse/Speech, Repetition, and Verbal Naming domains. This detailed process was applied to all tests, including the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA).
Analysis
We calculated the Jaccard Index to quantify test target similarity between each pairwise combination of aphasia tests, including the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA). The Jaccard Index formula is:
| J=su1+u2+s, |
|---|
where s is the number of similar test targets, u1 is unique targets for test 1, and u2 is unique targets for test 2. J ranges from 0 (no shared targets) to 1 (all targets shared), indicating similarity. Evans (1996) provides cut-offs for correlation strength: 0-.19 very weak, .2-.39 weak, .4-.59 moderate, .6-.79 strong, .8-1 very strong. We used these cut-offs to interpret Jaccard indices, especially in comparisons involving the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA).
Results
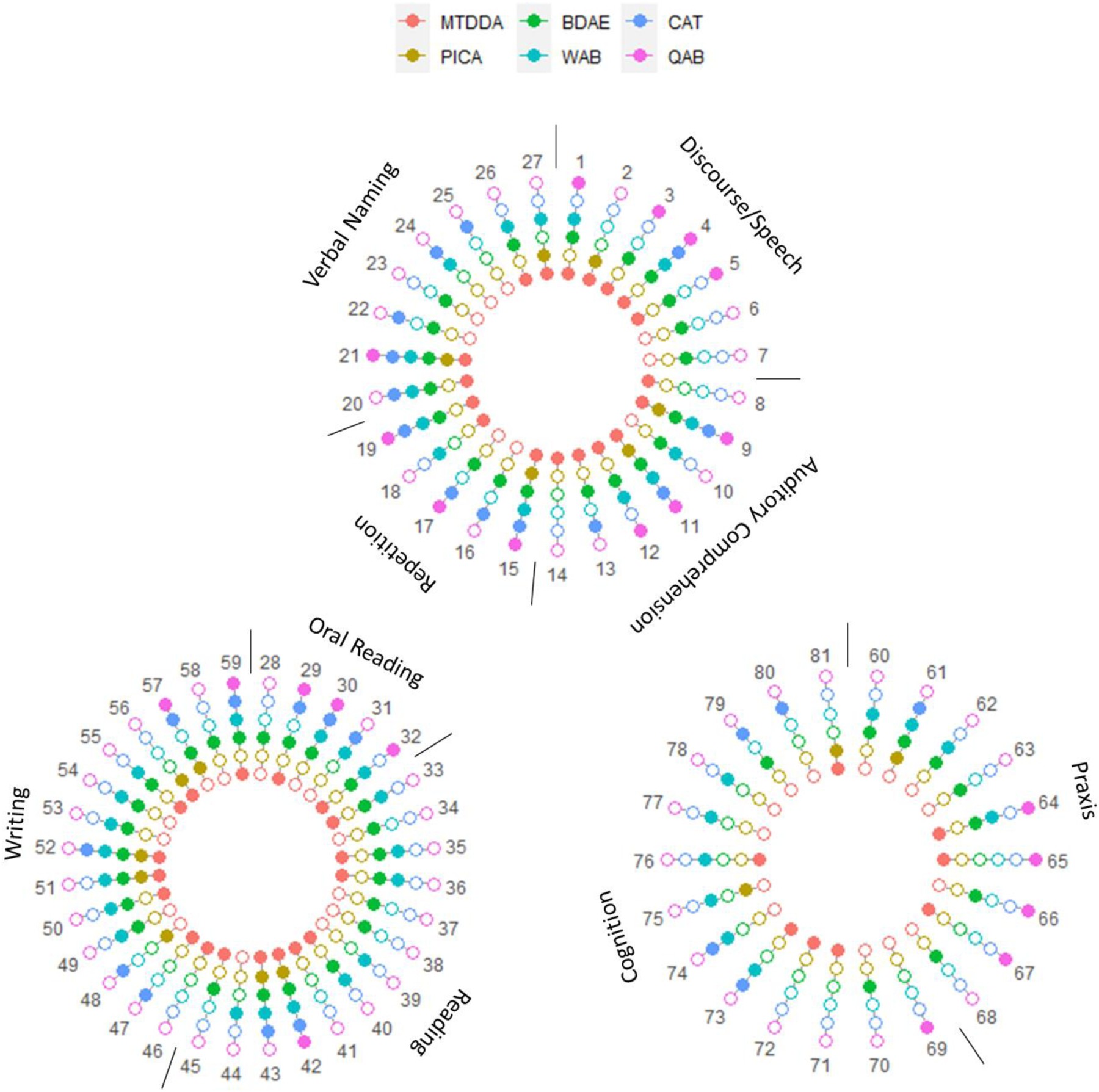
Figure 2 visualizes test target overlap across the six aphasia tests, including the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA). There were 81 unique test targets in total. Not all tests included every target. PICA had the fewest (N = 16), followed by QAB (N = 22), CAT (N = 28), WAB (N = 43), and MTDDA (N = 44). BDAE had the most (N = 53). Table 2 lists common labeled test targets by aphasia test (Supplemental Material contains original test target names).
Figure 2.
Table 2.
The common labeled test targets and the aphasia tests that assess those test targets.
| Test Target # and Common Label | MTDDA | PICA | BDAE | WAB | CAT | QAB | # of Aphasia Tests |
|---|---|---|---|---|---|---|---|
| Discourse/Speech | |||||||
| 1 | Conversational Questions | 1 | 0 | 1 | 1 | 0 | 1 |
| 2 | Novel Sentence Generation | 1 | 1 | 0 | 0 | 0 | 0 |
| 3 | Spoken Automatized Sequences | 1 | 0 | 1 | 0 | 0 | 1 |
| 4 | Spoken Picture Description | 1 | 0 | 1 | 1 | 1 | 1 |
| 5 | Narrative Discourse | 1 | 0 | 1 | 0 | 0 | 1 |
| 6 | Rhyme Recitation | 0 | 0 | 1 | 0 | 0 | 0 |
| 7 | Melody Production | 0 | 0 | 1 | 0 | 0 | 0 |
| Auditory Comprehension | |||||||
| 8 | Minimal Pairs – Words | 1 | 0 | 0 | 0 | 0 | 0 |
| 9 | Auditory Comprehension – Words | 1 | 1 | 1 | 1 | 1 | 1 |
| 10 | Auditory Comprehension – Complex Words | 0 | 0 | 1 | 1 | 0 | 0 |
| 11 | Auditory Comprehension – Sentences | 1 | 1 | 1 | 1 | 1 | 1 |
| 12 | Auditory Commands | 1 | 0 | 1 | 1 | 0 | 1 |
| 13 | Auditory Comprehension – Paragraphs | 1 | 0 | 1 | 0 | 1 | 0 |
| 14 | Word Span Task | 1 | 0 | 0 | 0 | 0 | 0 |
| Repetition | |||||||
| 15 | Repetition – Words | 1 | 1 | 1 | 1 | 1 | 1 |
| 16 | Repetition – Nonwords | 0 | 0 | 1 | 0 | 1 | 0 |
| 17 | Repetition – Complex Words | 0 | 0 | 1 | 0 | 1 | 1 |
| 18 | Repetition – Phrases | 1 | 0 | 0 | 1 | 0 | 0 |
| 19 | Repetition – Sentences | 1 | 0 | 1 | 1 | 1 | 1 |
| 20 | Repetition – Digits | 1 | 0 | 1 | 1 | 1 | 0 |
| Verbal Naming | |||||||
| 21 | Confrontation Naming – Nouns | 1 | 1 | 1 | 1 | 1 | 1 |
| 22 | Confrontation Naming – Verbs | 0 | 0 | 1 | 0 | 1 | 0 |
| 23 | Confrontation Naming – Adjectives | 0 | 0 | 1 | 0 | 0 | 0 |
| 24 | Word Fluency | 0 | 0 | 0 | 1 | 1 | 0 |
| 25 | Letter Fluency | 0 | 0 | 0 | 0 | 1 | 0 |
| 26 | Responsive Naming | 1 | 0 | 1 | 1 | 0 | 0 |
| 27 | Sentence Completion | 1 | 1 | 0 | 1 | 0 | 0 |
| Oral Reading | |||||||
| 28 | Oral Reading – Letters | 0 | 0 | 1 | 0 | 0 | 0 |
| 29 | Oral Reading – Words | 1 | 0 | 1 | 0 | 1 | 1 |
| 30 | Oral Reading – Complex Words | 0 | 0 | 1 | 1 | 1 | 1 |
| 31 | Oral Reading – Nonwords | 0 | 0 | 0 | 1 | 1 | 0 |
| 32 | Oral Reading – Sentences | 1 | 0 | 1 | 1 | 0 | 1 |
| Reading | |||||||
| 33 | Written Letter Matching | 1 | 0 | 1 | 1 | 0 | 0 |
| 34 | Written Word Matching | 0 | 0 | 1 | 0 | 0 | 0 |
| 35 | Spoken-Written Letter Matching | 1 | 0 | 1 | 1 | 0 | 0 |
| 36 | Spoken – Written Word Matching | 1 | 0 | 1 | 1 | 0 | 0 |
| 37 | Visual Lexical Decision | 0 | 0 | 1 | 0 | 0 | 0 |
| 38 | Homophone Matching | 0 | 0 | 1 | 0 | 0 | 0 |
| 39 | Spelled Word Recognition | 0 | 0 | 0 | 1 | 0 | 0 |
| 40 | Oral Spelling | 1 | 0 | 1 | 1 | 0 | 0 |
| 41 | Reading Rate | 1 | 0 | 0 | 0 | 0 | 0 |
| 42 | Reading Comprehension – Words | 1 | 1 | 1 | 1 | 1 | 1 |
| 43 | Reading Comprehension – Sentences | 1 | 1 | 1 | 1 | 1 | 0 |
| 44 | Reading Commands | 0 | 0 | 0 | 1 | 0 | 0 |
| 45 | Reading Comprehension – Paragraphs | 1 | 0 | 1 | 0 | 0 | 0 |
| Writing | |||||||
| 46 | Copying Symbols | 1 | 0 | 0 | 0 | 0 | 0 |
| 47 | Copying Letters | 1 | 0 | 0 | 0 | 1 | 0 |
| 48 | Copying Words | 0 | 1 | 0 | 0 | 1 | 0 |
| 49 | Copying Sentences | 0 | 0 | 1 | 1 | 0 | 0 |
| 50 | Writing Automatized Sequences | 1 | 0 | 1 | 1 | 0 | 0 |
| 51 | Writing Dictated Letters | 1 | 1 | 1 | 1 | 0 | 0 |
| 52 | Writing Dictated Words | 1 | 1 | 1 | 1 | 1 | 0 |
| 53 | Writing Dictated Complex Words | 0 | 0 | 1 | 1 | 0 | 0 |
| 54 | Writing Dictated Nonwords | 0 | 0 | 1 | 1 | 0 | 0 |
| 55 | Writing Dictated Sentences | 1 | 0 | 1 | 1 | 0 | 0 |
| 56 | Writing Novel Sentences | 1 | 1 | 0 | 0 | 0 | 0 |
| 57 | Written Naming – Nouns | 0 | 1 | 1 | 0 | 1 | 1 |
| 58 | Written Naming – Verbs | 0 | 0 | 1 | 0 | 0 | 0 |
| 59 | Written Picture Description | 1 | 0 | 1 | 1 | 1 | 1 |
| Praxis | |||||||
| 60 | Communicative Gestures (Hand/Limb) | 0 | 0 | 1 | 1 | 0 | 0 |
| 61 | Object Use Gestures | 0 | 1 | 1 | 1 | 1 | 0 |
| 62 | Facial Gestures | 0 | 0 | 1 | 1 | 0 | 0 |
| 63 | Imitation of Gestures | 0 | 0 | 1 | 0 | 0 | 0 |
| 64 | Mouth Movements | 1 | 0 | 1 | 1 | 0 | 1 |
| 65 | Rapid Phoneme Repetition | 1 | 0 | 0 | 0 | 0 | 1 |
| 66 | Rapid Word Repetition | 0 | 0 | 1 | 0 | 0 | 1 |
| 67 | Vowel Elongation | 1 | 0 | 0 | 0 | 0 | 1 |
| 68 | Rhythm Tapping | 0 | 0 | 1 | 0 | 0 | 0 |
| Cognitive | |||||||
| 69 | Alertness | 0 | 0 | 0 | 0 | 0 | 1 |
| 70 | Number Matching | 0 | 0 | 1 | 0 | 0 | 0 |
| 71 | Making Change | 1 | 0 | 0 | 0 | 0 | 0 |
| 72 | Clock Setting | 1 | 0 | 0 | 0 | 0 | 0 |
| 73 | Arithmetic | 1 | 0 | 0 | 1 | 1 | 0 |
| 74 | Line Bisection | 0 | 0 | 0 | 1 | 1 | 0 |
| 75 | Drawing Shapes | 0 | 1 | 0 | 1 | 0 | 0 |
| 76 | Drawing Objects | 1 | 0 | 0 | 1 | 0 | 0 |
| 77 | Block Design | 0 | 0 | 0 | 1 | 0 | 0 |
| 78 | Pattern Matching | 0 | 0 | 0 | 1 | 0 | 0 |
| 79 | Semantic Association | 0 | 0 | 1 | 0 | 1 | 0 |
| 80 | Recognition memory | 0 | 0 | 0 | 0 | 1 | 0 |
| 81 | Visual Matching | 1 | 1 | 0 | 0 | 0 | 0 |
The 81 test targets were grouped into 9 domains. Table 3 shows the overlap between test-specific domain labels and our common labels. Our common domains were discourse/speech, auditory comprehension, repetition, verbal naming, oral reading, reading, writing, praxis, and cognition. Notably, our final domain labels align with Weisenberg & McBride’s (1935) pioneering work, identifying similar assessment areas.
Table 3.
Overlap between test-specific subdomain labels and determined common labels.
| Aphasia Tests |
|---|
| Common Labels |
| Discourse/Speech |
| Auditory Comprehension |
| Repetition |
| Verbal Naming |
| Oral Reading |
| Reading |
| Writing |
| Praxis |
| Cognition |
Of the 81 test targets, 24 (29.6%) were idiosyncratic, appearing in only one test. Another 24 (29.6%) were in 2 tests, 13 (16.0%) in 3 tests, and 10 (12.3%) in 4 tests. Few targets appeared in most tests (Table 4). 5 targets (6.1%) were in 5 tests, and 5 (6.1%) were in all 6 tests, including the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA).
Table 4.
Most common test targets across aphasia tests.
| Appears in all 6 aphasia tests | Appears in 5 of 6 aphasia tests |
|---|---|
| – Auditory Comprehension – Words – Auditory Comprehension – Sentences – Repetition – Words – Confrontation Naming – Nouns – Reading Comprehension – Words | – Spoken Picture Description – Repetition – Sentences – Reading Comprehension – Sentences – Writing Dictated Words – Written Picture Description |
Table 5 shows Jaccard indices for all pairwise comparisons. Indices were predominantly weak (following Evans, 1996 cut-offs). Two were very weak (PICA-BDAE: J = .169; PICA-QAB: J = .187). The strongest (N = 3) were moderate (MTDDA-BDAE: J = .405; MTDDA-WAB: J = .450; BDAE-WAB: J = .476). Supplemental Material provides s, u1, and u2 values for Jaccard Indices.
Table 5.
The Jaccard Index for each pairwise comparison of aphasia tests.
| MTDDA | PICA | BDAE | WAB | CAT |
|---|---|---|---|---|
| PICA | 0.250 | |||
| BDAE | 0.405 | 0.169 | ||
| WAB | 0.450 | 0.229 | 0.476 | |
| CAT | 0.267 | 0.294 | 0.327 | 0.314 |
| QAB | 0.346 | 0.187 | 0.339 | 0.250 |
Note: Color is used in reference to the cut-offs provided by Evans (1996). Green indicates moderate correlation strengths (.4 – .59), yellow indicates weak correlation strengths (.2 – .39), and orange indicates very weak correlation strengths (0 – .19).
Discussion
We compared test targets of six diagnostic aphasia tests, including the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA), to assess content overlap as a way to understand the operational definition of aphasia. All tests included targets in domains used for aphasia subtype diagnosis (discourse/speech, auditory comprehension, verbal naming, repetition), aligning with the classical localization model. The strongest content similarities were between the MTDDA, BDAE, and WAB. PICA had the lowest similarity, possibly due to its fewer test targets (N=16). Overall, aphasia tests show inconsistent test targets, despite assessing similar domains and the same construct, aphasia.
These findings raise questions. First, how much content overlap is needed to confirm adequate aphasia assessment? This assumes aphasia is a unitary construct, implying a single comprehensive test is possible.
However, aphasia may be an emergent constellation of interactions between domains, influenced by brain-behavior relationships. This is the perspective in a network analysis of language assessment data from individuals with aphasia (Ashaie & Castro, 2021), including tests of naming, comprehension, discrimination, repetition, and memory. Auditory comprehension, verbal short-term memory, and picture naming were most central. Comparing this to Table 4, the most common targets across our analyzed tests (auditory comprehension of words/sentences, word repetition, confrontation naming of nouns, reading comprehension of words) shows considerable overlap. The Ashaie and Castro (2021) study did not include reading or writing tests. This correspondence suggests that despite low Jaccard indices, the analyzed aphasia tests share critical common test targets, and this includes the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA).
However, the second and fifth most central tests in Ashaie and Castro (2021) had analogues in our data set included in only one or two tests. These were semantic short-term memory (analogue: semantic association #79) and auditory minimal pair discrimination (analogue: minimal pair discrimination #8). Their centrality suggests including them in aphasia assessment could improve predictive utility and diagnostic sensitivity and specificity.
Second, aphasia test validity is often evaluated by correlations between test scores. For example, PICA Overall Score correlates highly with CAT Modality Mean T-score (Winans-Mitrik et al., 2014) and WAB AQ (Sanders & Davis, 1978). However, PICA and WAB repetition scores correlated less strongly (Sanders & Davis, 1978), and WAB and BDAE fluency scores even less (Wertz et al., 1984). Our finding of low overall content similarity complicates interpreting these correlations. Low content similarity, unlike outcome score correlations, may stem from low content overlap or other test construction, administration, and scoring aspects. For example, PICA administration is highly standardized with a 16-point scoring scale capturing promptness, efficiency, and responsiveness, while WAB administration is less specified, with correct/incorrect scoring and varying weighting. These differences are not captured in our content analysis, but might explain differences between tests like the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA) and others.
Conversely, high correlations don’t necessarily imply high content overlap. Fried (2017) showed high convergent validity between depression measures with minimal symptom overlap. High correlations may be driven by a small set of shared targets. As noted, we found consistent test targets across aphasia tests. Behavioral data on these consistent targets across tests is needed to confirm this hypothesis, rather than broad classification or summary score correlations (e.g., Wertz et al., 1984). If confirmed, it raises questions about the necessity of other test items for characterizing aphasia. Given aphasia heterogeneity, a large battery may be needed for a full picture, but is clinically infeasible, hence short forms and batteries (e.g., QAB).
Third, our findings relate to other validity evidence beyond correlations and content analysis. Explaining specific responses is key to validation (Zumbo, 2009). Detailed models of responses to test items can improve aphasia assessment for diagnosis, treatment planning, and outcome measurement. This approach has been used in single-case studies (e.g., Howard & Gatehouse, 2006; Rapp & Caramazza, 2002) and more recently in group designs using modern psychometrics (Walker et al., 2018; Walker et al., 2022). Educational assessment examples also exist (e.g., Yang & Embretson, 2007). Our findings can help identify test content where developing detailed response models will have the greatest impact, potentially including items from the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA).
Fourth, while the analyzed tests focus on language impairment, other domains (cognitive, psychosocial) are important. Neural networks are interconnected, and lesions can disrupt multiple processes. A single brain area can be involved in multiple systems (Seghier, 2013; Rockland & Graves, 2023). Lesions can impact language and cognition simultaneously. Links exist between language and emotion (Satpute & Lindquist, 2021), suggesting stroke can cause both aphasia and psychosocial impacts. Disentangling relationships between language impairment, cognition, and psychosocial impacts is needed.
Interestingly, all analyzed tests, including the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA), had cognitive test targets, even older batteries. Intellect as aphasia component has been debated (Kertesz & McCabe, 1975; Zangwill, 1964), and Weisenberg and McBride (1935) addressed cognition’s role in aphasia. Attention, memory, and executive function are recognized as important in aphasia assessment. Batteries like the Cognitive Language Quick Test (Helm-Estabrooks, 2001) assess both language and cognition but don’t focus on aphasia diagnosis specifically.
Aphasia also impacts communication and the whole person. Berg et al. (2022) describe aphasia as a communication disability with psychosocial ramifications. Psychosocial areas need assessment for a complete picture. Communication confidence can impact language test performance, potentially lowering scores. Ignoring psychosocial influences can negatively affect outcome assessment validity. Only CAT, among our analyzed batteries, assessed psychosocial impacts (CAT Disability Questionnaire), but including it would have further reduced Jaccard indices, so we excluded it. Further investigation into psychosocial consequence assessment in aphasia batteries is necessary.
Limitations
This study has limitations. We analyzed only six language impairment-focused diagnostic tests, excluding psychosocial consequence tests and patient-reported outcomes. We also did not consider empirical behavioral data or test scores. The Jaccard index is sensitive to set/sample size, potentially explaining higher indices between MTDDA, BDAE, and WAB. Despite this, our analysis is useful for identifying frequently shared aphasia test targets.
Moving Forward
Many questions remain in aphasiology, and productive paths forward exist. First, incorporating current test validity views into aphasia test development is crucial. Validity should focus on score interpretations and intended uses (Kane, 2001; Messick, 1995; Zumbo, 2009).
Second, aphasia understanding evolves. Tests should reflect these changes. As Scheel et al. (2021) state, measure development is iterative with concept formation. Re-evaluating common aphasia tests and the construct of aphasia is timely, especially in light of the findings related to the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA).
Rohde et al.’s (2018) review concluded no valid speech-language test diagnoses post-stroke aphasia due to lack of sensitivity/specificity data. Addressing this can be informed by our content analysis, modern validity frameworks, and psychometric tools.
Modern psychometrics (differential item functioning, item response theory, Rasch analysis, network psychometrics) offers new ways to re-evaluate what aspects of aphasia to assess. Multidimensional adaptive testing could balance test breadth and clinical brevity. Modern psychometrics also mandates clinical relevance, cultural appropriateness, and sensitivity. Failures of cultural sensitivity in assessments (Eloi et al., 2021; Salo et al., 2022), including aphasia tests, demand a new approach. More qualitative work, broader consensus, and wider stakeholder engagement (persons with aphasia, families, SLPs, physicians, advocacy groups, government agencies), with diverse representation, are needed. Advancing aphasia assessment requires examining clinical aphasiology’s historical foundation, including social, geographical, and political influences.
Revisiting and developing new aphasia measures, including revisiting the role of the Minnesota Test for Differential Diagnosis of Aphasia (MTDDA), remains vital. As Benton (1967) remarked on test development, “we may well learn important new facts about aphasia. Finally, it may be anticipated that the very existence of an examination based on rigorous scientific criteria would have the effect of raising the quality of aphasia research throughout the world. This too, we would all agree, is a prerequisite for advancing our knowledge of this group of disorders of ever-increasing medical importance” (p.40).
Supplementary Material
1
NIHMS1935296-supplement-1.pdf (358.7KB, pdf)
Acknowledgements
S. A. A. was supported by the National Institute on Deafness and Other Communication Disorders of the National Institutes of Health under award number 1K23DC020757-01. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Footnotes
- We acknowledge that the Quick Aphasia Battery (QAB) is not as narrow in its localizationist perspective and takes a qualitatively different perspective on localization as compared to the Boston Diagnostic Aphasia Test (BDAE) and the Western Aphasia Battery (WAB). However, pulling directly from the test developers, Wilson et al. (2018) explicitly linked aspects of language putatively measured by the QAB to their neural substrates.
References
[References listed in the original article]
Associated Data
Supplementary Materials
1
NIHMS1935296-supplement-1.pdf (358.7KB, pdf)